Hari Saran Manandhar
Introduction
It is best not to have an SQL Server table containing duplicate rows as per the database design best practices. During the database design process primary keys/Unique Keys should be created to eliminate duplicate rows. However, sometimes we need to work with databases where these rules are not followed, or exceptions are possible (when these rules are bypassed knowingly). For example, when a staging table is used, and data is loaded from different sources (ETL process for data migration to build Data Warehouse) where duplicate rows are possible. When the loading process completes, table should be cleaned or clean data should be loaded to a permanent table, so after that duplicates are no longer needed. Therefore, the process of removing duplicates from the loading table comes into play.
Let’s see the data table below:
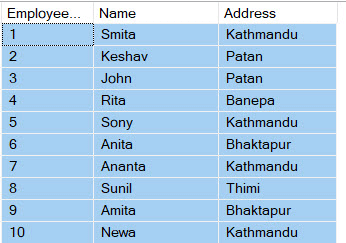
Source A data table:

Source B Data Table:
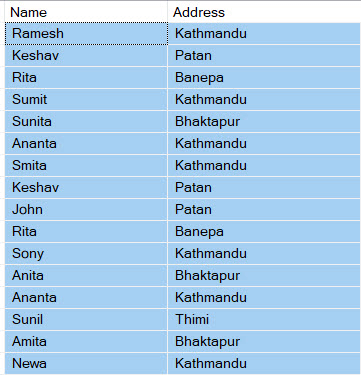
When data migration from both sources takes place, the staging table has data which include duplicate values that need to be removed for final migration:
SQL Query to remove duplicate records:
Method 1: Using a temp table:
- Insert Distinct record in temp table from Staging table.
- Delete all records from Staging table.
- Move records from temp table to Staging table
- Drop table temp
- Retrieve data from Staging
e.g. –
- SELECT DISTINCT * into #tmp From staging
- DELETE staging
- INSERT into staging SELECT * from #tmp
- DROP table #tmp
- SELECT * from staging
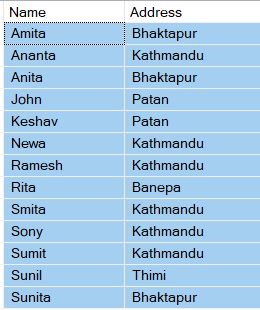
(The duplicate records have been removed, however this is a lengthy process and on the basis of performance it is not recommended. Also, if the staging table has one more column having different value and want to remove duplicate base on Name and Address Column, this method does not work.)
Method 2: Using CTE:
We can use common table expression (CTE) when want to remove duplicate records based on whole columns or partial columns. First CTE function row_number generate a row number in each row for the same records based on columns.
With CTE_Duplicates as (SELECT Name, Address, row_number() over(partition by Name,Address order by Name,Address ) rownumber from staging )
DELETE from CTE_Duplicates WHERE rownumber!=1
In above query, the function row_number generates a row number in each row for the same Name, Address group of result set. See screenshot of CTE table CTE_Duplicates.
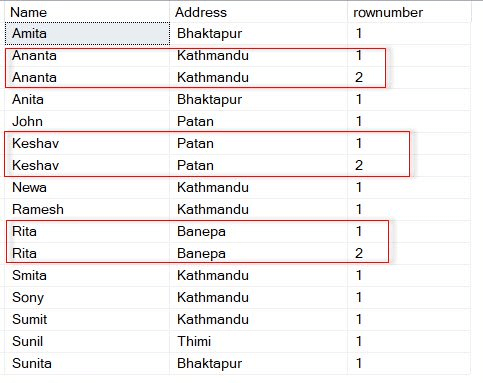
If the row number is greater than 1, it indicates a duplicate row and this means it needs to be deleted. The query “delete from CTE_Duplicates where rownumber!=1” will delete the duplicate rows from table Staging.
SELECT * FROM dbo.staging
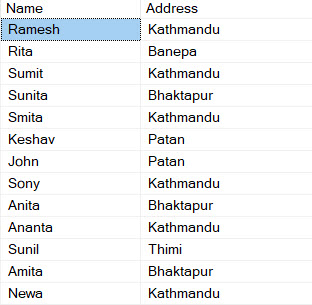
The duplicate records were removed. There are lots of other methods to write SQL query to remove duplicate, however CTE is greatly used for different SQL purposes like removing duplicate records.
If you would like to receive more such tips and tricks on CRM, ERP and other technologies, then subscribe to our blogs. Contact us today for a no-obligation consultation on 01296 328 689. Or email us at info@dogmagroup.co.uk.




